当前你的浏览器版本过低,网站已在兼容模式下运行,兼容模式仅提供最小功能支持,网站样式可能显示不正常。
请尽快升级浏览器以体验网站在线编辑、在线运行等功能。
1538:Extrapolation Using a Difference Table
题目描述
A very old technique for extrapolating a sequence of values is based on the use of a difference table. The difference table used in the extrapolation of a sequence of 4 values, say 3, 6, 10, and 15, might be displayed as follows:
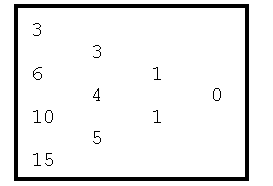
The original sequence of values appears in the first column of the table. Each entry in the second column of the table is formed by computing the difference between the adjacent entries in the first column. These values (in the second column) are called first differences. Each entry in the third column is similarly the difference between the adjacent entries in the second column; the third column entries are naturally called second differences. Computation of the last column in this example should now be obvious (but beware that this value is not always zero). Note that the last column will always contain only a single value. If we begin with a sequence of n values, the completed difference table will have n columns, with the single value in column n representing the single n-1st difference.
To extrapolate using a difference table we assume the n-1st differences are constant (since we have no additional information to refute that assumption). Given that assumption, we can compute the next entry in the n-2nd difference column, the n-3rd difference column, and so forth until we compute the next entry in the first column which, of course, is the next value in the sequence. The table below shows the four additional entries (in boxes) added to the table to compute the next entry in the example sequence, which in this case is 21. We could obviously continue this extrapolation process as far as desired by adding additional entries to the columns using the assumption that the n-1st differences are constant.

The original sequence of values appears in the first column of the table. Each entry in the second column of the table is formed by computing the difference between the adjacent entries in the first column. These values (in the second column) are called first differences. Each entry in the third column is similarly the difference between the adjacent entries in the second column; the third column entries are naturally called second differences. Computation of the last column in this example should now be obvious (but beware that this value is not always zero). Note that the last column will always contain only a single value. If we begin with a sequence of n values, the completed difference table will have n columns, with the single value in column n representing the single n-1st difference.
To extrapolate using a difference table we assume the n-1st differences are constant (since we have no additional information to refute that assumption). Given that assumption, we can compute the next entry in the n-2nd difference column, the n-3rd difference column, and so forth until we compute the next entry in the first column which, of course, is the next value in the sequence. The table below shows the four additional entries (in boxes) added to the table to compute the next entry in the example sequence, which in this case is 21. We could obviously continue this extrapolation process as far as desired by adding additional entries to the columns using the assumption that the n-1st differences are constant.
输入解释
The input for this problem will be a set of extrapolation requests. For each request the input will contain first an integer n, which specifies the number of values in the sequence to be extended. When n is zero your program should terminate. If n is non-zero (it will never be larger than 10), it will be followed by n integers representing the given elements in the sequence. The last item in the input for each extrapolation request is k, the number of extrapolation operations to perform; it will always be at least 1.
输出解释
In effect, you are to add k entries to each column of the difference table, finally reporting the last value of the sequence computed by such extrapolation. More precisely, assume the first n entries (the given values) in the sequence are numbered 1 through n. Your program is to determine the n+kth value in the sequence by extrapolation of the original sequence k times.
输入样例
4 3 6 10 15 1 4 3 6 10 15 2 3 2 4 6 20 6 3 9 12 5 18 -4 10 0
输出样例
Term 5 of the sequence is 21 Term 6 of the sequence is 28 Term 23 of the sequence is 46 Term 16 of the sequence is -319268
提示
no upper limit is given for k, and you might not be able to acquire enough memory to construct a complete difference table.
最后修改于 2020-10-29T06:06:40+00:00 由爬虫自动更新
共提交 0 次
通过率 --%
| 时间上限 | 内存上限 |
| 1000 | 10000 |
登陆或注册以提交代码